Data deduplication, compression, and compaction in QNAP
The QNAP QuTS hero operating system utilizes the ZFS file system, which inherently supports inline deduplication and inline compression. However, to enhance efficiency, especially considering the 4K block size, QNAP has also incorporated data compaction into QuTS hero. This process of compaction occurs prior to deduplication. Here's a breakdown of how it functions, in sequential order, all performed inline (meaning it occurs in real-time as data is being written):
Inline Compression happens first
Each file is subjected to inline compression. If the data within the file is compressible, it is first compressed using the LZ4 algorithm. This algorithm is lightweight, ensuring it does not heavily burden the system.
Compressed file will be smaller ( with compression ratio depending on data) , but it's worth noting that even after compression, files may still span across several partially filled 4K blocks.
In the figure below, you can see that the file size is reduced from 8 blocks to 6 blocks; however, file 1 and file 3 are 1.5 blocks each, occupying not 3 but 4 blocks , since both have a partially filled block.
When dealing with a large quantity of small files, these partially filled blocks can end up occupying a significant amount of space. The purpose of the compaction process ( which is the next step) is to consolidate multiple partially filled blocks into fewer blocks. This step is crucial, particularly in environments with numerous small files, as it significantly reduces the number of blocks required to store data
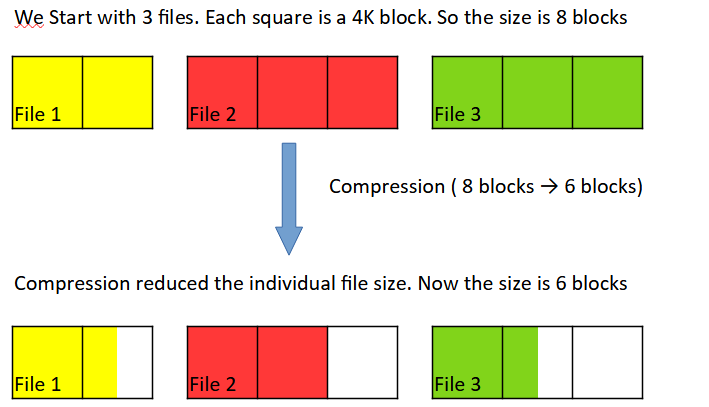
Inline Compaction to consolidate partially filled blocks
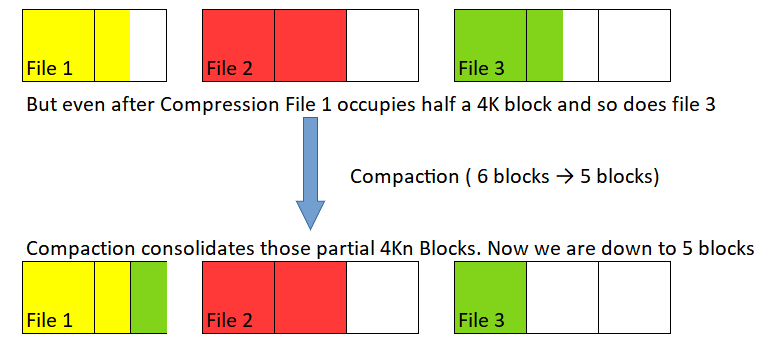
As we saw in last step Post-compression, many 4K blocks are only partially filled, especially if there are small files present, leading to numerous half-occupied 4K blocks. The compaction process leaves fully occupied 4K blocks untouched and consolidates partially filled 4K blocks to utilize space more efficiently.
So compaction combines the half-filled block from file 1 and the half-filled block from file 3 bringing the total number of blocks required for storage down from 6 to 5.
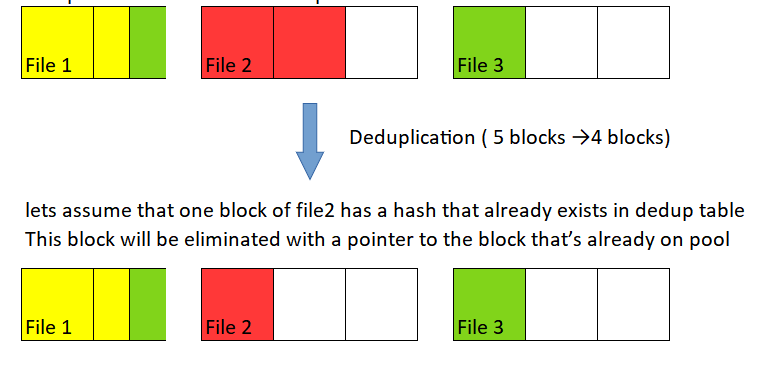
Finally Inline Deduplication
This final step involves everything stored in the pool and aims to further optimize storage. After compression and compaction, the system examines the files to identify similar blocks across different files. It utilizes a deduplication table to compare the hash of each block against others, identifying duplicates for removal. Any duplicate block it finds is removed and replaced by a pointer.
This sequence ensures that data storage on QNAP QuTS hero is as efficient as possible, leveraging compression, compaction, and deduplication. The only process out of the 3 that takes up memory is deduplication
This sequence ensures that data storage on QNAP QuTS hero is as efficient as possible, leveraging compression, compaction, and deduplication to optimize space and system performance.
QNAP QuTS hero uses ZFS file system so it natively has support inline Deduplication and inline compression. Howver the 4K block size may be further utilized with data compaction so QNAP introduced data compaction in QuTS hero also. Compaction is done before deduplication.
lets see how it works.
First the chronology , it happens in this order ( all inline so it happens on the fly as the data is arriving to be written)
Inline Compression > Inline compaction > Inline deduplication
Inline Compression runs on each file
If the data is compressible , then at the file level the data is compressed first using LZ4 algo. Its a lightweight algo so it doesn't tax the system.
Inline Compaction runs on the set of files
Now compression has left many 4K blocks half filled. If you have any small files, then for sure they have many 4K blocks half occupied. what compaction does is leave the full 4K blocks as they are , and consolidate the partially filled 4K blocks together.
Inline Deduplication Runs on multiple files
Now your set of files is as compressed and compact as it can be. next the system checks if there are similar blocks in any other file , it does so with the dedup table checking the hash of each block with other blocks.